This post walks through some of the thinking behind how we might approach the problem of converting a non-tail recursive function to a tail recursive one. The code we present also illustrates some interesting Scala techniques: implicit conversions of primitive classes to Ordered, type aliases and function passing. For those of you not already familiar with tail recursion, there are some great articles out there to get up to speed on the concept (for example, this one).
To summarize very briefly:
tail recursion is a characteristic of recursive methods wherein the very last action of any branch of the method is a recursive call to the method itself.
recursive functions that are not tail recursive have the annoying property of blowing out your stack because they save intermediate state in each stack frame — state which is then combined by the result of the recursive call. Given that stack memory is finite, and assuming that your input could be arbitrarily long (therefore requiring an arbitrarily large number of stack frames to store intermediate state) you will likely run into a stack overflow at some point.
Scala automatically optimizes tail recursive functions by converting the recursion into a loop. This article presents a really good simple example of how tail recursion in the source code is translated to a loop in the byte code.
Now that you are a tail recursion expert, let’s look at some code:
package scalaTry
class Merger[T]()(implicit e: T => Ordered[T]) {
def compare(a: T, b: T): Unit = {
if (a < b)
println("a less")
else
println("a NOT less")
}
final def merge(a: List[T],
b: List[T]): List[T] = {
(a,b) match{
case (Nil,Nil) =>
Nil
case (a1::tail, Nil) =>
a1::tail
case (Nil, b1::tail) =>
b1::tail
case (a1::tail1, b1::tail2) =>
if (a1 < b1) {
a1::b1::merge(tail1,tail2)
} else {
b1::a1::merge(tail1,tail2)
}
case default =>
throw new
IllegalStateException(
"Should never get here")
}
}
The merge method of the Merger class shown above recursively merges two sorted lists, a and b. The lowest level escape conditions are where one or both of the input lists are empty (Nil). In this case we either return Nil (where both are Nil), or we return the non-Nil list. If both lists are non-Nil, the logic is (conceptually) to create a two element list consisting of the heads of a and b (in their proper order), and append to this two element list the result of merging the tails of a and b (lines 22 and 24).
One interesting aspect of the Merger class, the use of Ordered, and the implicit conversion of T to an Ordered[T] highlighted on line 3, is not specifically related to tail recursion. This line genericizes (in Java-speak) the Merger class such that the merge method can accept Lists of any type T for which an implicit conversion to Ordering is available.
But let’s get back to tail recursion, or the lack of it in the merge method. As discussed above lines 22 and 24 are doing the conceptual equivalent of creating creating a two element list, then recursing on the tails of the input list. The two element list occupies memory on the stack until the recursive call to merge returns, at which point the two element list and the result of the recursive call are joined together. Clearly, more and more memory will be consumed as the input lists get larger.
So what to do? The merge2 function shown below shows one way we can avoid a stack overflow. In this function we explicitly create the list that is to be prepended to the result of merging the tails. But instead of keeping that list on the stack and joining it to the result of the recursive call on the tails, we explicitly pass it down to the recursive call as the prefixSoFar. At the point of each recursive call we know that the elements in prefixSoFar are less than or equal to the head items of either a or b (the variables a1 and b1). Thus when we create a new prefix (as on line 16), we know that prefixSoFar should come first, followed by either a1 then b1, or by b1, then a1 (as on line 20). When one or both of the input lists a and b are Nil, we return the prefixSo far, potentially tacking on any remaining elements in one of the non-Nil input lists (as on line 10). These remaining elements are guaranteed to be equal to or greater than any of the elements of the prefixSoFar (per the given Ordering).
A final comment on the merge2 method: note that Scala provides the handy annotation tailrec, used on line 2, to declare a function as tail recursive, and have the compiler double check that this declaration is correct. If you were to use this annotation right before the method declaration of a non-tail recursive function such as merge, you would get a compiler error.
def merge2(a: List[T], b: List[T]): List[T] = {
@scala.annotation.tailrec
def merge2(a: List[T],
b: List[T],
prefixSoFar: List[T]): List[T] = {
(a,b) match{
case (Nil,Nil) =>
prefixSoFar
case (a1::tail, Nil) =>
prefixSoFar ::: a1 :: tail
case (Nil, b1::tail) =>
prefixSoFar ::: b1 :: tail
case (a1::tail1, b1::tail2) =>
if (a1 < b1) {
val prefix: List[T] =
prefixSoFar ::: a1 :: b1 :: Nil
merge2(tail1, tail2, prefix)
} else {
val prefix: List[T] =
prefixSoFar ::: b1 :: a1 :: Nil
merge2(tail1, tail2, prefix)
}
case default =>
throw new
IllegalStateException(
"Should never get here")
}
}
merge2(a, b, Nil)
}
So, now we have a merge method that won’t blow out our stack. Next we need to test it, which we shall do with the code below. doMergeTest accepts two functions, one that merges two String lists, and another that merges two Int lists. We define the type aliases MergeStringLists and MergeIntLists that capture the signatures of these two functions. doMerge accepts arguments of the first signature as fun1, and the second signature as fun2. In the test ‘merging works’ we first pass in a function pair based on the merge function, and then pass in a function pair based on the tail recursive merge2 function. If you grab the project from this github repo and run it, my guess is that you would see all green. Try it out!
I recently went looking for a good Docker recipe to locally launch a Spark 2.4.3 cluster in stand-alone mode. Running in ‘local’ mode is good for roughing out your business logic and unit tests, but it will not flush out bugs that only surface in a fully distributed environment. That is where integration tests come in, and while some organizations will set up a test cluster for this purpose, you don’t want to be twiddling your thumbs when your network is down, or your admin decides to take down the test cluster you depend on for maintenance. This is where Docker comes to our rescue.
This project contains a fairly recent (2.2.0) Dockerfile and docker-compose.yml that will bring up a multi-node stand-alone Spark cluster, but I wanted 2.4.3. So, I forked the project and brought it up to date, plus I added a little example project to make it easy to test out.
Below I lay out the steps you can follow to get a stand-alone cluster up and running on whatever machine you use (provided you have git, docker and docker-compose already installed). Three caveats: (1) the docker-compose.yml is set to version “2” and if you use a later version than me, you might need to set it to “3”, (2) this was tested on Linux, but I am very sure that Docker commands on Mac will work the same — not at all sure about Windows, (3) I am assuming you have the proper version of Scala for Spark 2.4.3 installed (2.12.x) on your machine, and that you have downloaded Spark 2.4.3 locally on your machine to run spark-submit.
Getting The Cluster Up In Your Environment
Open two terminals, in each one cd to /tmp. In the first, type:
git clone git@github.com:buildlackey/docker-spark-standalone.git
cd docker-spark-standalone
docker-compose up
You will see logs for the client (client_1), master (master_1), and worker (worker_1) nodes of the cluster. Don’t worry if you see
Failed to connect to master/172.24.0.4:7077
in the worker_1 log at the start of the boot process. The worker is trying to connect to a master which is not fully up. This will work itself out, and in 5 seconds or so you should see:
master_1 | 19/08/25 02:56:35 INFO Master: Registering worker 172.24.0.2:36655 with 4 cores, 4.0 GB RAM
worker_1 | 19/08/25 02:56:35 INFO Worker: Successfully registered with master spark://master:7077
Now, in the second window type:
cd /tmp/docker-spark-standalone/spark-example
sbt package
This will create the .jar file you will submit to spark as follows:
You should then see output that looks something like this:
2019-08-24 20:08:25 WARN Utils:66 - Your hostname, chris-laptop resolves to a loopback address: 127.0.1.1; using 192.168.1.83 instead (on interface wlp4s0)
2019-08-24 20:08:25 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address
2019-08-24 20:08:25 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2019-08-24 20:08:25 INFO SparkContext:54 - Running Spark version 2.3.1
2019-08-24 20:08:25 INFO SparkContext:54 - Submitted application: Simple Application
..... Lots more junk...
2019-08-24 20:08:30 INFO CodeGenerator:54 - Code generated in 12.991607 ms
+-----+
|value|
+-----+
|hi ho|
+-----+
No luck Submitting From My IDE.
After importing the sample project into Intellij I thought there would be no problem running it via right click. But regretably, that was not my fate. I am continuing to see the error below when I run locally, which is really irksome.
java.io.InvalidClassException: org.apache.spark.rpc.netty.NettyRpcEndpointRef; local class incompatible:
In my previous article on streaming in Spark, we looked at some of the less obvious fine points of grouping via time windows, the interplay between triggers and processing time, and processing time vs. event time. This article will look at some related topics and contrast the older DStream-based API with the newer (and officially recommended) Structured Streaming API via an exploration of how we might rewrite an existing DStream based application using the newer API, with particular focus on sliding windows.
The first section of the article builds some intuition around slide intervals, windows, and the events they can potentially ‘subsume’ (definition to follow). Then we discuss some key differences between DStream and Structured Streaming-based processing, present a motivating use case, and then dive into some code. The final section provides a rigorous proof of some of the claims made in the first section.
Sliding Windows Intuition
Do any patterns emerge when we look at how the timestamped events ingested into our applications are bucketed to particular windows in a series of sliding windows across some time line? Are there any structural patterns that we can use to classify the types of windows into which our events fall? There are indeed, and we will explore those patterns here. (Sliding windows are discussed at a general level in both the DStream programming documentation — in the subsection entitled Window Operations of this section, and in the Structured Streaming guide.)
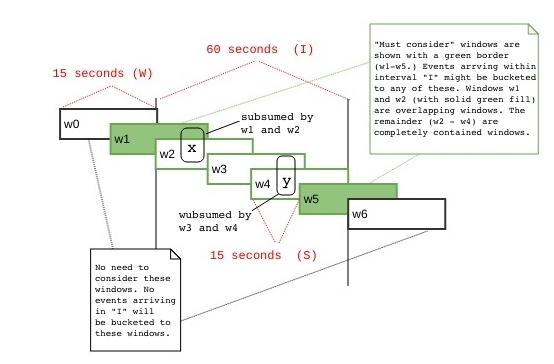
When we write unit tests or spot check the results of our application code, there will always be some bounded time interval (let’s call it I) that ‘brackets’ the timestamps of the earliest and latest incoming events in our test set. Clearly, we care what’s happening with events inside of I, not outside of it. It would also be helpful to know, given our test set and how we choose I, these two things: (a) the number of windows we must consider when checking our results (here a must consider window is one which could potentially subsume an incoming event) , and (b) for any specific event, e, in our test set, how many windows will subsumee. When a window, w, subsumes an event e, the following must hold: startTime(w) <= timestamp(e) < endTime(w).
Reasoning will be easier if we make the simplifying assumptions that
our window length w is equal to some integral multiple k (k >= 1) of our slide interval, s,
our interval I begins at zero, and is equal to some integral multiple n (n >= 1) of w. (This means s < w < I, s*k =w, and n*w=I)
We shall see shortly that we must consider some windows which are not completely contained within I: in particular, we will see that some of our events are subsumed within what we call overlapping windows – those whose start time stamp is less than the time stamp that marks the start of I (but whose end time stamp lies within I), and those whose end time stamp is greater than the time stamp that marks the end of I (but whose start time stamp lies within I.) We will also provide a proof that the total number of windows we must consider is k + kn – 1, the total number of completely containedwindows is kn – k + 1, and the totalnumber of overlapping windows is 2(k-1).
For now, we will show how these formulas work via an example where our time units are in seconds (although the formula can also be applied when developing applications that work in terms of finer or coarser grained units (e.g., milliseconds as we get more fine grained, or hours or days as the granularity of our bucketing gets coarser.) In our example the window interval (W) is set to 30 seconds, the slide interval (S) is set to 15 seconds, and the time interval I which bounds the earliest and latest arriving events is set to 60 seconds. Given these values, n = 2, and k = 2.
I = 60
W = 30
S = 15
where n and k = 2, since W (30) = 2 * S (15), and I (60) = 2 * W
In the diagram below there are a total of 5 must consider windows (w1 through w5, in green), and this is the same number that our formula gives us:
The total number of overlapping and completely contained windows is 2 (w1 and w5), and 3 (w2 – w5) respectively. These results accord with the cardinality formulas for these two window types:
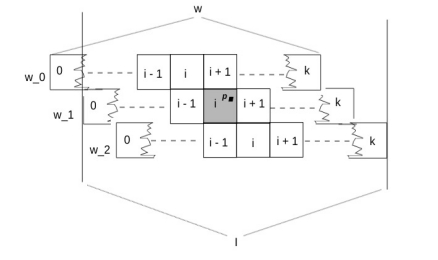
Here we make the claim that for any arbitrary point, p, on the half-open Interval I’ from 0 (inclusive) to I (exclusive) there are k windows that subsume p. In this article we will not offer a formal mathematical proof, but will instead illustrate with two examples. First off, referring to the diagram above, pick a point on I’ (e.g., x,or y, or any other point you prefer,) then note that the chosen point will fall within 2 windows (and also note that, for the scenario illustrated in the above diagram, k = 2.) For a more general example, refer to the diagram below. This diagram shows windows of length w, where w is k times the slide interval. We have selected an arbitrary point p within I’ and we see that it is subsumed by (among other windows) window w_1, where it lies in the i-th slide segment (a term which we haven’t defined, but whose meaning should be intuitively obvious.)
Visually, it seems clear that we can forward slide w_1 i – 1 times and still have p subsumed by window w_1. After the i-th slide the startTime of the resultant window would be greater than p. Similarly we could backward slide w_1 k – i times and still have p subsumed by the result of the slide. After the (k – i + 1)th backward slide the endTime of the resultant window would be less than p. This makes for a total of 1 + (i – 1) + (k – i) position variations of w_1 that will subsume point p (we add one to account for the original position of w_1.) Arranging like terms, we have 1 – 1 + i – i + k = k possible variants. Each of these variants would map to one of w actual windows that would subsume point p. So this illustrates the general case.
Key Differences In How The Two Frameworks Handle Windows
Now let’s move from more abstract concepts towards a discussion of some key high level differences between the two frameworks we will be examining. First we note that DStream sliding windows are based on processing time – the time of an event’s arrival into the framework, whereas Structured Streaming sliding windows are based on the timestamp value of one of the attributes of incoming event records. Such timestamp attributes are usually set by the source system that generated the original event; however, you can also base your Structured Streaming logic on processing time by targeting an attribute whose value is generated by the current_time stamp function.
So with DStreams the timestamps of the windows that will subsume your test events will be determined by your system clock, whereas with Structured Streaming these factors are ‘preordained’ by one of the timestamp-typed attributes of those events. Fortunately, for DStreams there are some libraries — such as Holden Karau’s Spark Testing Base that let you write unit tests using a mock system clock, with the result that you obtain more easily reproducible results. This is less of a help when you are spot checking the output of your non-test code, however. In these cases each run will bucket your data into windows with different timestamps.
By contrast, Structured Streaming will always bucket the same test data into the same windows (again, provided the timestamps on your test events are not generated via current_timestamp — but even if they are you can always mock that data using fixed timestamps.) This makes it much easier to write tests and spot check results of non-test code, since you can more reliably reproduce the same results. You can also prototype the code you use to process your event data using non-streaming batch code (using the typed Dataset API, or Dataframes with sparkSession.read.xxx, instead of sparkSession.readStream.xxx). But note that not every series of transformations that you can apply in batch is guaranteed to work when you move to streaming. An example of something that won’t transfer well (unless you use a trick that we reveal later) is code that uses chained aggregations, as discussed here.
A final key difference we will note is that, with DStreams, once a sliding window’s end time is reached no subsequently arriving events can be bucketed to that window (without significant extra work.) The original DStreams paper does attempt to address this by sketching (in section 3.2, Timing Considerations) two approaches to handling late arriving data, neither of which seems totally satisfactory. The first is to simply wait for some “slack time” before processing each batch (which would increase end-to-end latency), and the second is to correct late records at the application level, which seems to suggest foregoing the convenience of built in (arrival time-based) window processing features, and instead managing window state by hand.
Structured Streams supports updating previously output windows with late arriving data by design. You can set limits on how long you will wait for late arriving data using watermarks, which we don’t have space to explore in much detail here. However, you can refer to the section Watermarking to Limit State while Handling Late Data of this blog post for a pictorial walk through of how the totals of a previously output window are updated with late arriving data (pay particular attention to the totals for ‘dev2’ in window 12:00-12:10). The ability to handle late arriving data can be quite useful in cases where sources that feed into your application might be intermittently connected, such as if you were getting sensor data from vehicles which might, at some point, pass through a tunnel (in which case older data would build up and be transmitted in a burst. )
Motivating Use Case
We’ll look at code shortly, but let us first discuss our use case. We are going to suppose we work for a company that has deployed a variety of sensors across some geographic area and our boss wants us to create a dashboard that shows, for each type of sensor, what the top state of that sensor type is across all sensors in all regions, and across some sliding time window (assuming that, at any point in time, a given sensor can be in exactly one out of some finite set of states.) Whether we are working with DStreams or Structured Streams the basic approach will be to monitor a directory for incoming text files, each of which contain event records of the form:
At any given time the program that sends us events will poll all sensors in the region, and some subset will respond with their states. For the sake of this toy example, we assume that if the sender found multiple sensors with the same state (say 3) within some polling interval, then the message it transmits will have X repeated 3 times, resulting in an event that would look something like the line below.
2008-09-15T15:53:00,temp,london,X,X,X
Our toy program will also simply zero in on sensors of type ‘temp’ and will punt on aggregating along the dimension of sensor type.
How We Test The Two Solutions
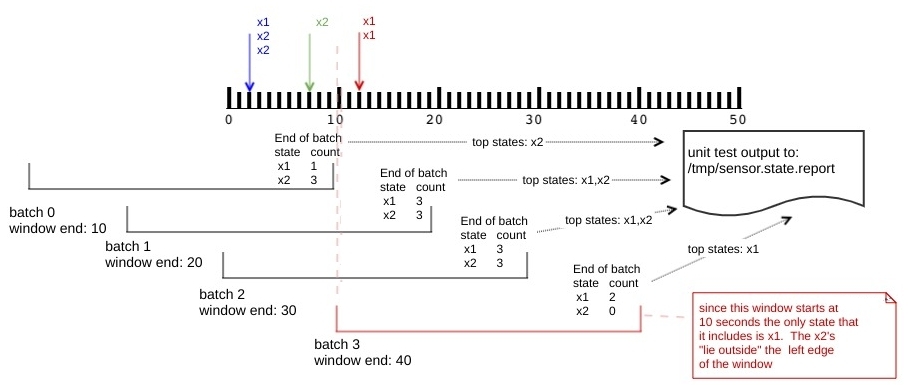
The solutions we developed with both the old and new API need to pass the same test scenario. This scenario involves writing out files containing sensor events to a monitored directory, in batches that are sequenced in time as per the diagram below.
Both solution approaches will bucket incoming events into 30 second windows, with a slide interval of 10 seconds, and then write out the the top most frequently occurring events using the formatting below (out of laziness we opted to output the toString representation of the data structure we use to track the top events):
for window 2019-06-29 11:27:00.0 got sensor states: TreeSet(x2)
for window 2019-06-29 11:27:10.0 got sensor states: TreeSet(x1, x2)
The next diagram we present shows the code that writes out event batches at 2, 7, and 12 seconds. Note that each call to writeStringToFile is associated with a color coded set of events that matches the color coding in the first diagram presented in this section.
The main flow of the test that exercises both solutions is shown below, while the full listing of our test code is available here.
"Top Sensor State Reporter" should {
"correctly output top states for target sensor using DStreams" in {
setup()
val ctx: StreamingContext =
new DstreamTopSensorState().
beginProcessingInputStream(
checkpointDirPath, incomingFilesDirPath, outputFile)
writeRecords()
verifyResult
ctx.stop()
}
"correctly output top states for target sensor using structured streaming" in {
import com.lackey.stream.examples.dataset.StreamWriterStrategies._
setup()
val query =
StructuredStreamingTopSensorState.
processInputStream(doWrites = fileWriter)
writeRecords()
verifyResult
query.stop()
}
}
DStreams Approach WALK-THROUGH
The main entry point to the DStream solution is beginProcessingInputStream(), which takes a checkpoint directory, the path of the directory to monitor for input, and the path of the file where we write final results.
Note the above method invokes StreamingContext.getOrCreate(), passing, as the second argument, a function block which invokes the method which will actually create the context, shown below
def createContext(incomingFilesDir: String, checkpointDirectory: String, outputFile: String): StreamingContext = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("OldSchoolStreaming") val ssc = new StreamingContext(sparkConf, BATCH_DURATION) ssc.checkpoint(checkpointDirectory) ssc.sparkContext.setLogLevel("ERROR") processStream(ssc.textFileStream(incomingFilesDir), outputFile) ssc }
createContext() then invokes processStream(), shown in full below.
def processStream(stringContentStream: DStream[String],
outputFile: String): Unit = {
val wordsInLine: DStream[Array[String]] =
stringContentStream.map(_.split(","))
val sensorStateOccurrences: DStream[(String, Int)] =
wordsInLine.flatMap {
words: Array[String] =>
var retval = Array[(String, Int)]()
if (words.length >= 4 && words(1) == "temp") {
retval =
words.drop(3).map((state: String) => (state, 1))
}
retval
}
val stateToCount: DStream[(String, Int)] =
sensorStateOccurrences.
reduceByKeyAndWindow(
(count1: Int,
count2: Int) => count1 + count2,
WINDOW_DURATION, SLIDE_DURATION
)
val countToState: DStream[(Int, String)] =
stateToCount.map {
case (state, count) => (count, state)
}
case class TopCandidatesResult(count: Int,
candidates: TreeSet[String]
val topCandidates: DStream[TopCandidatesResult] =
countToState.map {
case (count, state) =>
TopCandidatesResult(count, TreeSet(state))
}
val topCandidatesFinalist: DStream[TopCandidatesResult] =
topCandidates.reduce {
(top1: TopCandidatesResult, top2: TopCandidatesResult) =>
if (top1.count == top2.count)
TopCandidatesResult(
top1.count,
top1.candidates ++ top2.candidates)
else if (top1.count > top2.count)
top1
else
top2
}
topCandidatesFinalist.foreachRDD { rdd =>
rdd.foreach {
item: TopCandidatesResult =>
writeStringToFile(
outputFile,
s"top sensor states: ${item.candidates}", true)
}
}
}
The second argument to the call specifies the output file, while the first is the DStream[String] which will feed the method lines that will be parsed into events. Next we use familiar ‘word count’ logic to generate the stateToCountDStream of 2-tuples containing a state name and a count of how many times that state occurred in the current sliding window interval.
We reduce countToState into a DStream of TopCandidatesResult structures
case class TopCandidatesResult(count: Int,
candidates: TreeSet[String])
which work such that, in the reduce phase when two TopCandidatesResult instances with the same count are merged we take whatever states are ‘at that count’ and merge them into a set. This way duplicates are coalesced, and if two states were at the same count then the resultant merged TopCandidatesResult instance will track both of those states.
Finally, we use foreachRDD to write the result to our report file.
STRUCTURED STREAMING APPROACH WALK-THROUGH And Discussion
Use of rank() over Window To Get the Top N States
Before we get to our Structured Streaming-based solution code, let’s look at rank() over Window, a feature of the Dataframe API that will allow us to get the top N sensor states (where N = 1.) We need to take a top N approach because we are looking for the most common states (plural!), and there might be more than one such top occurring state. We can’t just sort the list in descending order by count and take the first item on the list. There might be a subsequent state that had the exact same count value.
The code snippet below operates in the animal rather than sensor domain. It uses rank() to find the top occurring animal parts within each animal type. Before you look at the code it might be helpful to glance at the inputs (see the variable df,) and the outputs first.
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
object TopNExample {
def main(args: Array[String]) {
val spark = SparkSession.builder
.master("local")
.appName("spark session example")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
spark.sparkContext.setLogLevel("ERROR")
val df = spark.sparkContext.parallelize(
List(
("dog", "tail", 1),
("dog", "tail", 2),
("dog", "tail", 2),
("dog", "snout", 5),
("dog", "ears", 5),
("cat", "paw", 4),
("cat", "fur", 9),
("cat", "paw", 2)
)
).toDF("animal", "part", "count")
val hiCountsByAnimalAndPart =
df.
groupBy($"animal", $"part").
agg(max($"count").as("hi_count"))
println("max counts for each animal/part combo")
hiCountsByAnimalAndPart.show()
val ranked = hiCountsByAnimalAndPart.
withColumn(
"rank",
rank().
over(
Window.partitionBy("animal").
orderBy($"hi_count".desc)))
println("max counts for each animal/part combo (ranked)")
// Note there will be a gap in the rankings for dog
// specifically '2' will be missing. This is because
// we used rank, instead of dense_rank, which would have
// produced output with no gaps.
ranked show()
val filtered = ranked .filter($"rank" <= 1).drop("rank")
println("show only animal/part combos with highest count")
filtered.show()
}
}
Below is the output of running the above code. Note that within the category dog the highest animalPart counts were for both ‘ears’ and ‘snout’, so both of these are included as ‘highest occurring’ for category dog.
max counts for each animal/part combo
+------+-----+--------+
|animal| part|hi_count|
+------+-----+--------+
| dog| ears| 5|
| dog|snout| 5|
| cat| fur| 9|
| dog| tail| 2|
| cat| paw| 4|
+------+-----+--------+
max counts for each animal/part combo (ranked)
+------+-----+--------+----+
|animal| part|hi_count|rank|
+------+-----+--------+----+
| dog| ears| 5| 1|
| dog|snout| 5| 1|
| dog| tail| 2| 2|
| cat| fur| 9| 1|
| cat| paw| 4| 2|
+------+-----+--------+----+
show only animal/part combos with highest count
+------+-----+--------+
|animal| part|hi_count|
+------+-----+--------+
| dog| ears| 5|
| dog|snout| 5|
| cat| fur| 9|
+------+-----+--------+
Structured Streaming Approach Details
The full listing of our Structured Streaming solution is shown below, and its main entry point is processInputStream() which accepts a function that maps a DataFrame to a StreamingQuery. We parameterize our strategy for creating a streaming query so that during ad-hoc testing and verification , we write out our results to the console (via consoleWriter). Then, when running the code in production (as production as we can get for a demo application) we use the fileWriter strategy which will use foreachBatch to (a) perform some additional transformations of each batch of intermediate results in the stream (using rank() which we discussed above), and then (b) invoke FileHelpers.writeStringToFile() to write out the results.
processInputStream() creates fileStreamDS, a DataSet of String lines extracted from the files which are dropped in the directory that we monitor for input. fileStreamDS is passed as an argument to toStateCountsByWindow, whereupon it is flatMapped to sensorTypeAndTimeDS, which is the result of extracting zero or more String 2-tuples of the form (stateName, timeStamp) from each line. sensorTypeAndTimeDS is transformed to timeStampedDF which coerces the string timestamp into the new, properly typed, column timestamp. We then create a sliding window over this new column, and return a DataFrame which counts occurrences of each state type within each time window of length WINDOW and duration SLIDE.
That return value is then passed to doWrites which (given that we are using the fileWriter strategy) will rank order the state counts within each time window, and filter out all states whose count was NOT the highest for a given window (giving us topCountByWindowAndStateDf which holds the highest occurring states in each window.) Finally, we collect topCountByWindowAndStateDf and for each window we convert the states in that window to a Set, and then each such set — which holds the names of the highest occurring states — is written out via FileHelpers.writeStringToFile.
Working Around Chaining Restriction with forEachBatch
Note that the groupBy aggregation performed in toStateCountsByWindow is followed by the Window-based aggregation to compute rank in rankAndFilter,which is invoked from the context of a call to forEachBatch. If we had directly chained these aggregations Spark would have thrown the error “Multiple streaming aggregations are not supported with streaming DataFrames/Datasets.” But we worked around this by wrapping the second aggregation with forEachBatch. This is a useful trick to employ when you want to chain aggregations with Structured Streaming, as the Spark documentation points out (with a caveat about forEachBatch providing only at-least-once guarantees):
Many DataFrame and Dataset operations are not supported in streaming DataFrames because Spark does not support generating incremental plans in those cases. Using foreachBatch, you can apply some of these operations on each micro-batch output. However, you will have to reason about the end-to-end semantics of doing that operation yourself.
Could We Have Prototyped Our Streaming Solution Using Batch ?
One reason why the Spark community advocates Structured Streaming over DStreams is that the delta between the former and batch processing with DataFrames is a lot smaller than the programming model differences between DStreams and batch processing with RDDs. In fact, Databricks tells us that when developing a streaming application “you can write [a] batch job as a way to prototype it and then you can convert it to a streaming job.”
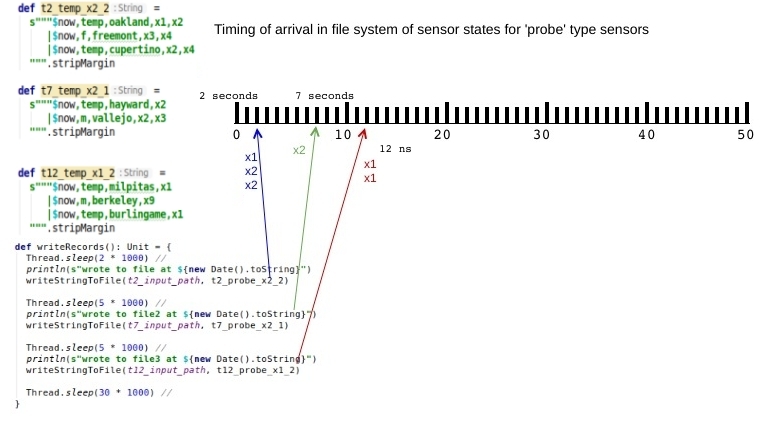
I did try this when developing the demo application presented in this article, but since I was new to Structured Streaming my original prototype did not transfer well (mainly because I hit the wall of not being able to chain aggregations and had not yet hit on the forEachBatch work-around.) However, we can easily show that the core of our Structured Streaming solution would work well when invoked from a batch context, as shown by the code snippet below:
"Top Sensor State Reporter" should {
"work in batch mode" in {
setup()
Thread.sleep(2 * 1000) //
writeStringToFile(t2_input_path, t2_temp_x2_2)
Thread.sleep(5 * 1000) //
writeStringToFile(t7_input_path, t7_temp_x2_1)
Thread.sleep(5 * 1000) //
writeStringToFile(t12_input_path, t12_temp_x1_2)
val sparkSession = SparkSession.builder
.master("local")
.appName("example")
.getOrCreate()
val linesDs =
sparkSession.
read. // Note: batch-based 'read' not readStream !
textFile(incomingFilesDirPath)
val toStateCountsByWindow =
StructuredStreamingTopSensorState.
toStateCountsByWindow(
linesDs,
sparkSession)
TopStatesInWindowRanker.
rankAndFilter(toStateCountsByWindow).show()
}
// This sort-of-unit-test will produce the following
// console output:
// +-------------------+--------+
// | window_start| states|
// +-------------------+--------+
// |2019-07-08 15:06:10| [x2]|
// |2019-07-08 15:06:20|[x1, x2]|
// |2019-07-08 15:06:30|[x2, x1]|
// |2019-07-08 15:06:40| [x1]|
// +-------------------+--------+
The advantage that this brings is not limited to being able to prototype using the batch API. There is obvious value in being able to deploy the bulk of your processing logic in both streaming and batch modes.
Structured Streaming Output Analyzed In Context of Window and Event Relationships
Now let’s take a look at the output of a particular run of our Structured Streaming solution. We will check to see if the timestamped events in our test set were bucketed to windows in conformance with the models that we presented earlier in the Intuition section of this article.
The first file write is at 16:41:04 (A), and in total two x2 events were generated within 6 milliseconds of each other (one from the sensor in Oakland at 41:04.919 (B), and another for the sensor in Cupertino at 41:04.925 (C).) We will treat these two closely spaced events as one event e (since all the x2 occurrences are collapsed into a set anyway), and look at the windows into which e was bucketed. The debug output detailing statesperWindow (D), indicates e was bucketed into three windows starting at 16:40:40.0, 16:40:50.0, and 16:41:00.0. Note that our model predicts each event will be bucketed into k windows, where k is the multiple by which our window interval exceeds our slide interval. Since our slide interval was chosen to be 10, and our window interval 30, k is 3 for this run and event e is indeed bucketed into 3 windows.
wrote to file at Sun Jul 07 16:41:04 PDT 2019 (A)
line at Sun Jul 07 16:41:06 PDT 2019:
2019-07-07T16:41:04.919,temp,oakland,x1,x2 (B)
line at Sun Jul 07 16:41:06 PDT 2019:
2019-07-07T16:41:04.925,f,freemont,x3,x4
line at Sun Jul 07 16:41:06 PDT 2019:
2019-07-07T16:41:04.925,temp,cupertino,x2,x4 (C)
line at Sun Jul 07 16:41:06 PDT 2019:
wrote to file2 at Sun Jul 07 16:41:09 PDT 2019
wrote to file3 at Sun Jul 07 16:41:14 PDT 2019
at Sun Jul 07 16:41:18 PDT 2019. Batch: 0 / statesperWindow: List( (D)
for window 2019-07-07 16:40:40.0 got sensor states: TreeSet(x2),
for window 2019-07-07 16:40:50.0 got sensor states: TreeSet(x2),
for window 2019-07-07 16:41:00.0 got sensor states: TreeSet(x2))
line at Sun Jul 07 16:41:18 PDT 2019:
2019-07-07T16:41:14.927,temp,milpitas,x1 (E)
line at Sun Jul 07 16:41:18 PDT 2019:
2019-07-07T16:41:14.927,m,berkeley,x9 (E)
line at Sun Jul 07 16:41:18 PDT 2019:
2019-07-07T16:41:14.927,temp,burlingame,x1 (E)
line at Sun Jul 07 16:41:18 PDT 2019:
line at Sun Jul 07 16:41:18 PDT 2019:
2019-07-07T16:41:09.926,temp,hayward,x2
line at Sun Jul 07 16:41:18 PDT 2019:
2019-07-07T16:41:09.926,m,vallejo,x2,x3
line at Sun Jul 07 16:41:18 PDT 2019:
at Sun Jul 07 16:41:27 PDT 2019. Batch: 1 / statesperWindow: List(
for window 2019-07-07 16:40:40.0 got sensor states: TreeSet(x2),
for window 2019-07-07 16:40:50.0 got sensor states: TreeSet(x1, x2),
for window 2019-07-07 16:41:00.0 got sensor states: TreeSet(x1, x2),
for window 2019-07-07 16:41:10.0 got sensor states: TreeSet(x1))
Process finished with exit code 0
Let’s see if the number of overlapping predicted by our model is correct. Since k = 3, our model would predict
2 * (k – 1)
2 * (3 – 1)
2 *2 = 4
overlapping windows, two whose beginning timestamp is before the start of our interval I, and two whose ending timestamp occurs after the end of I. We haven’t defined I, but from the simplifying assumptions we made earlier we know that I must be a multiple of our slide interval, which is 10 seconds, and the start of I must be earlier or equal to the timestamp of the earliest event in our data set. This means that the maximal legitimate timestamp for the start of I would be 16:41:00, so let’s work with that. We then see we have two overlapping windows “on the left side” of I, one beginning at 16:40:40, and the other at 16:40:50.
On the “right hand side” we see that the maximal event timestamp in our dataset is 16:41:14.927 (E). This implies that the earliest end time for I would be 16:41:30 (which would make the length of I 1x our window length). However, there is only one overlapping window emitted by the framework which has an end timestamp beyond the length of I, and that is the window from 16:41:10 to 16:41:40. This is less than the two which the model would predict for the right hand side. Why?
This is because our data set does not have any events with time stamps between the interval 16:41:20 and 16:41:30 (which certainly falls within the bounds of I). If we had such events then we would have seen those events subsumed by a second overlapping window starting from 16:41:20. So what we see from looking at this run is that the number of overlapping windows our model gives us for a given k is an upper bound on the number of overlapping windows we would need to consider as possibly bracketing the events in our data set.
FOR THE INTREPID: A Proof Of The Must Consider Windows Equation
Here is a bonus for the mathematically inclined, or something to skip for those who aren’t.
GIVEN
an interval of length I starting at 0, a window interval of length of w, a slide interval of s where w is an integral multiple k (k >= 1) of s, and interval I is an integral multiple n (n >= 1) of w, and a timeline whose points can take either negative or positive values
THEN
there are exactly kn – k + 1 completely contained windows, where for each such window c, startTime(c) >= 0 and endTime(c) <= I
there are exactly 2(k-1)overlapping windows, where for each such window c’, EITHER
startTime(c’) < 0 AND endTime(c’) > 0 AND endTime(c’) < I , OR
startTime(c’) > 0 AND startTime(c’) < I AND endTime(c’) > I
PROOF
Claim 1
Define C to be the set of completely contained windows with respect to I, and denote the window with startTime of 0 and endTime of w to be w_0, and note that since startTime(w_0) >= 0 and endTime(w_0) = w < I, w_0 is a member of C, and is in fact that element of C with the lowest possible startTime.
Define a slide forward operation to be a shift of a window by s units, such that the original window’s startTime and endTime are incremented by s. Any window w’ generated by a slide forward operation will belong to C as long as endTime(w’) <= I.
Starting with initial member w_0, we will grow set C by applying i slide forward operations (where i starts with 1). The resultant window from any such slide forward operation will be denoted as w_i. Note that for any w_i, endTime(wi) = w + s * i. This can be trivially proved by induction, noting that when i = 0 and no slide forwards have been performed endTime(w_0) = w, and after 1 slide forwardendTime(w_i) = w + s.
We can continue apply slide forwards and adding to C until
w + s * i = I,
After the i+1-th slide forward the resultant window’s end time would exceed I, so we stop at i. Rewriting I and w in the above equation in terms of S, we get:
k * s + s * i = k * s * n
because I = w * n, and w = k * s. Continuing we rewrite:
s * i = n(k * s) – k * s
s * i = s(n*k -k)
i = nk – k
Thus our set C will contain w_0, plus the result of applying nk-k slide forwards, for a total of at least nk – k + 1 elements
Now we must prove that set C contains no more than nk – k + 1 elements.
The argument is that no element of C can have an earlier start time than w_0, and as we performed each slide forward we grew the membership of C by adding the window not yet in C whose start time was equal to or lower than any other window not yet in the set. Thus every element that could have been added (before getting to an element whose startTime was greater than I) was indeed added. No eligible element was skipped.
QED (claim 1)
Claim 2
Let w_0 be the “rightmost” window in the set of completely contained windows, that is, the window with maximally large endTime,such that endTime(w_0) = I. It follows that startTime(w_0) = I – w.
Now let’s calculate the number of slide forwards we must execute — starting with w_0 — in order to derive a window w’withstartTime(w’) = I.
Every slide forward up to, but not including the ith will result in an overlapping window, whose startTime is less than I and whose endTime is greater than I. Furthermore, eachslide forwardon a window D results in a window whose startTime is s more than startTime(D).
Thus:
startTime(w_0) + s * i = I
I – w + s * i = I
-w + s * i = 0
s * i = w
s * i = k * s
i = k
So k – 1 slide forwards will generate overlapping windows starting from the rightmost completely contained window. A similar argument will show that starting from the “left most” completely contained window, and performing slide backwards (decreasing the startTime and endTime of a window being operated on by s) will result in k-1 overlapping windows. So, the total number of overlapping windows we can generate is 2 * (k – 1). Now, we actually proved this is the lower bound on the cardinality of the set of overlapping windows. But we can employ the same arguments made for claim 1 to show that there can be no more overlapping windows than 2 * (k – 1).
QED (claim 2)
COROLLARY:
Given the above definitions of windows, slides, and interval I, the total number of windows that could potentially subsume an arbitrary point on the half-open interval I’, ranging from from 0 (inclusive) to I (exclusive), is k + kn – 1. If a window w’subsumes a point p, then startTime(w’) <= p and p < endTime(w’).
PROOF
Given an arbitrary point p within I’, let window w’ be the window with startTime floor( p/w ), and endTime floor(p/w) + w.
Since p >= 0, and w > 0,floor( p/w ) >= 0, and since p < I, floor(p/w) must be at least w less than I, this implies endTime(w’) = floor(p/w) + w cannot be greater than I. Thus w’ is a completely contained window. Further, startTime(w’) = floor(p/w) must be less than or equal to p, and since floor(p/w) is the least integral multiple of w less than or equal to p we know endTime(w’) = floor(p/w) + w cannot be less than or equal to p. Therefore, endTime(w’) must be greater than p, so w’subsumesp.
Now we show that at least one overlapping window could subsume a point on I’. Consider the point 0. This point will be subsumed by the overlapping window w” with startTime -s and endTime w-s. w” is an overlapping window by definition since its startTime is less than 0 and since its endTime is < I. Since -s < 0 < s, we have at least one overlapping window which potentially subsumes a point on I’.
Now we show that, given an aribitrary point p, if a window, w‘, is neither overlapping nor completely contained, then w’ cannot possibly subsume p. If w’ is not completely contained, then either (i) startTime(w’) < 0, or (ii) endTime(w’) > I.
In case (i), we know that if endTime(c’) > 0 AND endTime(c’) <= I, then w’ is overlapping, which is a contradiction. Thus either (a) endTime(c’) <= 0 or (b) endTime(c’) > I.
If (a) is true, then startTime(w’) < endTime(w’) <= 0. Thus w’ cannot subsume p, since p >= 0, and in order for w’ to subsumep, p must be strictly less than endTime(w’), which it is not. (b) cannot be true, since if it were the length of window w’ would be greater than I, which violates the GIVEN conditions of the original proof.
In case (ii), either either (a) startTime(w’) <= 0, or startTime(w’) >= I, otherwise w’ is an overlapping window, which is a contradiction. Thus either (a) startTime(w’) <= 0, or (b) startTime(w’) >= I.
(a) cannot be true by the same argument about the length of w’ violating original proof definitions,
given in (i-b). If (b) were true, then I <= startTime(w’) < endTime(w’), and since p < I, w’ could not subsumep.
The set of overlapping and completely contained windows (denoting these as O and C, respectively) is by definition mutually exclusive. Since we have shown that an arbitrary point p will always be subsumed by a completely contained window and may potentially be subsumed by an overlapping window, the cardinality of the set of windows that could potentially subsumep is equal to cardinality(O) –– ( 2(k-1) ) plus cardinality(C) — ( kn – k + 1 ), Thus cardinality(O U C) is:
kn – k + 1 + 2(k-1), or expanding terms
kn – k + 1 + 2k – 2, or
kn + 2k – k + 1 – 2, or
kn + k – 1, QED
Conclusion
After implementing solutions to our sensor problem using both DStreams and Structured Streaming I was a bit surprised by the fact that the solution using the newer API took up more lines of code than the DStreams solution (although some of the extra is attributable to supporting the console strategy for debugging). I still would abide by the Databricks recommendation to prefer the newer API for new projects, mostly due to deployment flexibility (i.e., the ability to push out your business logic in batch or streaming modes with minimal code changes), and the the fact that DStreams will probably receive less attention from the community going forward.
At this point it is also probably worth pointing out how we would go about filling some of the major holes in our toy solution if we were really developing something for production use. First off, note that our fileWriter strategy uses “complete” output mode, rather than “append”. This makes things simpler when outputting to a File Sink, but “complete” mode doesn’t support watermarking (that is, throwing away old data after a certain point) by design. This means Spark must allocate memory to maintain state for all window periods ever generated by the application, and as time goes on this guarantees an OOM. A better solution would have been to use “update” mode and a sink that supports fine grained updates, like a database.
A final “what would I have done different” point concerns the length of windowing period and hard coded seconds-based granularity of the windows and slides in the application. A 30 second window period makes for long integration test runs, and more waiting around. It would have been better to express the granularity in terms of milliseconds and parameterize the window and slide interval, while investing some more time in making the integration tests run faster. But that’s for next time, or for you to consider on your current project if you found the advice given here helpful. If you want to tinker with the source code it is available on github.
Apache Spark currently supports two approaches to streaming: the “classic” DStream API (based on RDDs), and the newer Dataframe-based API (officially recommended by Databricks) called “Structured Streaming.” As I have been learning the latter API it took me a while to get the hang of grouping via time windows, and how to best deal with the interplay between triggers and processing time vs. event time. So you can avoid my rookie mistakes, this article summarizes what I learned through trial and error, as well as poking into the source code. After reading this article you should come away with a good understanding of how event arrival time (a.k.a. processing time) determines the window into which any given event is aggregated when using processing time triggers.
A MOTIVATING USE Case
To motivate the discussion, let’s assume we’ve been hired as Chief Ranger of a national park, and that our boss has asked us to create a dashboard showing real time estimates of the population of the animals in the park for different time windows. We will set up a series of motion capture cameras that send images of animals to a furry facial recognition system that eventually publishes a stream of events of the form:
<timestamp>,<animalName>,count
Each event record indicates the time a photo was taken, the type of animal appearing in the photo, and how many animals of that type were recognized in that photo. Those events will be input to our streaming app. Our app converts those incoming events to another event stream which will feed the dashboard. The dashboard will show — over the last hour, within windows of 10 minutes — how many animals of each type have been seen by the cameras — like this:
Initially Incorrect Assumptions About How The Output Would Look
As a a proof-of-concept, our streaming app will take input from the furry facial recognition system over a socket, even though socket-based streams are explicitly not recommended for production. Also, our code example will shorten the interval at which we emit events to 5 seconds. We will test using a Processing Time Trigger set to five seconds, and the input below, where one event is received every second.
Note: for presentation purposes the input events are shown broken out into groups that would fit within 5 second windows, where each window begins at a time whose ‘seconds’ value is a multiple of five. Thus the first 3 events would be bucketed to window 16:33:15-16:33:20, the next five to window 16:33:20-16:33:25, and so on. Let’s ignore the first window totals of rat:3,hog:2 and come back to those later.
event-time-stamp animal count
2019-06-18T16:33:18 rat 1 \
2019-06-18T16:33:19 hog 2 =>> [ 33:20 - 33:25 ]
2019-06-18T16:33:19 rat 2 / rat:3,hog 2
2019-06-18T16:33:22 dog 5
2019-06-18T16:33:21 pig 2
2019-06-18T16:33:22 duck 4
2019-06-18T16:33:22 dog 4
2019-06-18T16:33:24 dog 4
2019-06-18T16:33:26 mouse 2
2019-06-18T16:33:27 horse 2
2019-06-18T16:33:27 bear 2
2019-06-18T16:33:29 lion 2
2019-06-18T16:33:31 tiger 4
2019-06-18T16:33:31 tiger 4
2019-06-18T16:33:32 fox 4
2019-06-18T16:33:33 wolf 4
2019-06-18T16:33:34 sheep 4
Our trigger setting causes Spark to execute the associated query in micro-batch mode, where micro-batches will be kicked off every 5 seconds. The Structured Streaming Programming Guide says the following about triggers:
If [a] … micro-batch completes within the [given] interval, then the engine will wait until the interval is over before kicking off the next micro-batch.
If the previous micro-batch takes longer than the interval to complete (i.e. if an interval boundary is missed), then the next micro-batch will start as soon as the previous one completes (i.e., it will not wait for the next interval boundary).
If no new data is available, then no micro-batch will be kicked off.
Given our every-5-second trigger, and given the fact that we are grouping our input events into windows of 5 seconds, I initially assumed that all our batches would align neatly to the beginning of a window boundary and contain only aggregations of events that occurred within that window, which would have given results like this:
What We Actually Got, And Why It Differed From Expected
The beginner mistake I made was to conflate processing time (the time at which Spark receives an event) with event time (the time at which the source system which generated the event marked the event as being created.)
In the processing chain envisioned by our use case there would actually be three timelines:
the time at which an event is captured at the source (in our use case, by a motion sensitive camera). The associated timestamp is part of the event message payload. In my test data I have hard coded these times.
the time at which the recognition system — having completed analysis and classification of the image — sends the event over a socket
the time when Spark actually receives the event (in the socket data source) — this is the processing time
The difference between (2) and (3) should be minimal assuming all machines are on the same network — so when we refer to processing time we won’t worry about the distinction between these two. In our toy application we don’t aggregate over processing time (we use event time), but the time of arrival of events as they are read from the socket is definitely going to determine the particular five second window into which any given an event is rolled up.
One of the first things I observed was that the first batch consistently only reported one record, as shown below:
In order to understand why the first batch did not contain totals rat:3 and hog:2 (per my original, incorrect assumption, detailed above), I created an instrumented version of org.apache.spark.sql.execution.streaming.TextSocketSource2 which prints the current time at the point of each call to getBatch() and getOffset(). You can review my version of the data source here (the file contains some comments — tagged with //CLONE — explaining the general technique of copying an existing Spark data source so you can sprinkle in more logging/debugging statements.) I also instrumented the program I was using to mock the facial recognition system such that it would print out not only the content of the event payload being sent, but also the time at which the event was written to the socket. This test program is discussed in the next section. The Spark output that I got for first batch was roughly this:
socket read at Thu Jun 20 19:19:36 PDT 2019
line:2019-06-18T16:33:18,rat,1
at Thu Jun 20 19:19:36 PDT 2019 getOffset: Some(0)
at Thu Jun 20 19:19:36 PDT 2019 getBatch: start:None end: 0
-------------------------------------------
Batch: 0
-------------------------------------------
+------------------------------------------+------+------------+
|window |animal|sum(howMany)|
+------------------------------------------+------+------------+
|[2019-06-18 16:33:15, 2019-06-18 16:33:20]|rat |1 |
+------------------------------------------+------+------------+
socket read at Thu Jun 20 19:19:37 PDT 2019
line:2019-06-18T16:33:19,hog,2
The mock facial recognition system was set to emit one event every second, so it printed the following (abbreviated) output for this run:
input line: 2019-06-18T16:33:18,rat,1
emitting to socket at Thu Jun 20 19:19:36 PDT 2019:
2019-06-18T16:33:18,rat,1
input line: 2019-06-18T16:33:19,hog,2
emitting to socket at Thu Jun 20 19:19:37 PDT 2019:
2019-06-18T16:33:19,hog,2
Here is an explanation of why we only reported one record in the first batch. When the class that backs the “socket” data source is initialized it starts a loop to read from the configured socket and adds event records to a buffer as they are read in (which in our case is once every second.) When the MicrobatchStreamExecution class invokes our trigger the code block will first invoke constructNextBatch() which will attempt to calculate ‘offsets’ (where the current head of the stream is in terms of the last index into the buffer of available data), then the method runBatch() will call the getBatch() method of our socket data source, passing in the range of offsets to grab (using the offset calculation in the previous step.) TextSocketSource.getBatch will cough up for whatever events the read loop had buffered up.
Prior to the the getBatch() call, which occurs at 19:19:36. The only event received prior (at 19:19:36) was rat,1. So this is the only event reported in the first batch. Note that our times are reported in resolution of seconds, so that the rat,1 event was reported as arriving concurrently with the getBatch() call; I am taking it on faith that with finer grained resolutions we would see the time stamp for the ‘socket read ….rat,1’ message be slightly before the timestamp of the first getBatch() call.
In the course of execution of our (5 second) trigger we only make one call to getBatch() at the start of processing, and we pick up the one event that is available at that time. In the time period covered by the first 5 second trigger other events could be arriving over the socket and getting placed into the buffer ‘batches’. But those events won’t be picked up until the next trigger execution (i.e., the subsequent batch.) (Please see the final section of the article for a diagram that illustrates these interactions.)
We provide a listing showing the actual batch results we obtained, below.
Note that certain time windows take a couple of batch cyles to settle into correctness. An example is the total for dog given for window “2019-06-18 16:33:20 – 2019-06-18 16:33:25” in Batch 1. The total should be 13, and in fact the final dog record seems to come in as of Batch 2, and that batch’s report for |[2019-06-18 16:33:20, 2019-06-18 16:33:25]|dog is correct (13 dog sightings for the period.)
For the purposes of our application this seems quite acceptable. Anyone looking at the dashboard display might see some “jitter” around the totals for a particular time window for a particular animal. Since our original requirement was to show totals in 10 minute windows, and since we know there will be some straggler window totals that require two batches to ‘settle’ to correctness, we would probably want to implement the real solution via a sliding window with window length 10 minutes and slide interval of 10 or 15 seconds which would mean (I’m pretty sure, but can’t claim to have tested) that any incomplete counts for a given window would become correct in that 10 to 15 second interval.
Writing Test Data Over a Socket
The code for our simulated facial recognition component is shown below. It should work fine for you in a Mac or Linux environment (and maybe if you use Cygwin under Windows, but no guarantees.) The test script is bash based, but it actually automtically compiles and executes the Scala code below the “!#”, which I thought was kind of cool.
#!/bin/sh
exec scala "$0" "$@"
!#
import java.io.{OutputStreamWriter, PrintWriter}
import java.net.ServerSocket
import java.util.Date
import java.text.SimpleDateFormat
import scala.io.Source
object SocketEmitter {
/**
* Input params
*
* port -- we create a socket on this port
* fileName -- emit lines from this file ever sleep seconds
* sleepSecsBetweenWrites -- amount to sleep before emitting
*/
def main(args: Array[String]) {
args match {
case Array(port, fileName, sleepSecs) => {
val serverSocket = new ServerSocket(port.toInt)
val socket = serverSocket.accept()
val out: PrintWriter =
new PrintWriter(
new OutputStreamWriter(socket.getOutputStream))
for (line <- Source.fromFile(fileName).getLines()) {
println(s"input line: ${line.toString}")
var items: Array[String] = line.split("\\|")
items.foreach{item =>
val output = s"$item"
println(
s"emitting to socket at ${new Date().toString()}: $output")
out.println(output)
}
out.flush()
Thread.sleep(1000 * sleepSecs.toInt)
}
}
case _ =>
throw new RuntimeException(
"USAGE socket <portNumber> <fileName> <sleepSecsBetweenWrites>")
}
Thread.sleep(9999999 *1000) // sleep until we are killed
}
}
To run it, save the script to some path like ‘/tmp/socket_script.sh’, then execute the following commands (Mac or Linux):
The script waits for a connection (which comes from our Structured Streaming app), and then writes one even per second to the socket connection.
SOURCE Code For Streaming Window Counts
The full listing of our streaming window counts example program is provided below, and you can also pull a runnable version of the project from github, here.
package com.lackey.stream.examples.dataset
import java.sql.Timestamp
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.log4j._
import org.apache.spark.sql.execution.streaming.TextSocketSource2
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{DataStreamWriter, OutputMode, Trigger}
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Future
object GroupByWindowExample {
case class AnimalView(timeSeen: Timestamp, animal: String, howMany: Integer)
val fmt = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss")
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder
.master("local")
.appName("example")
.getOrCreate()
// Here is the trick I use to turn on logging only for specific
// Spark components.
Logger.getLogger("org").setLevel(Level.OFF)
//Logger.getLogger(classOf[MicroBatchExecution]).setLevel(Level.DEBUG)
import sparkSession.implicits._
val socketStreamDs: Dataset[String] =
sparkSession.readStream
.format("org.apache.spark.sql.execution.streaming.TextSocketSourceProvider2")
.option("host", "localhost")
.option("port", 9999)
.load()
.as[String] // Each string in dataset == 1 line sent via socket
val writer: DataStreamWriter[Row] = {
getDataStreamWriter(sparkSession, socketStreamDs)
}
Future {
Thread.sleep(4 * 5 * 1000)
val msgs = TextSocketSource2.getMsgs()
System.out.println("msgs:" + msgs.mkString("\n"))
}
writer
.format("console")
.option("truncate", "false")
.outputMode(OutputMode.Update())
.start()
.awaitTermination()
}
def getDataStreamWriter(sparkSession: SparkSession,
lines: Dataset[String])
: DataStreamWriter[Row] = {
import sparkSession.implicits._
// Process each line in 'lines' by splitting on the "," and creating
// a Dataset[AnimalView] which will be partitioned into 5 second window
// groups. Within each time window we sum up the occurrence counts
// of each animal .
val animalViewDs: Dataset[AnimalView] = lines.flatMap {
line => {
try {
val columns = line.split(",")
val str = columns(0)
val date: Date = fmt.parse(str)
Some(AnimalView(new Timestamp(date.getTime), columns(1), columns(2).toInt))
} catch {
case e: Exception =>
println("ignoring exception : " + e);
None
}
}
}
val windowedCount = animalViewDs
//.withWatermark("timeSeen", "5 seconds")
.groupBy(
window($"timeSeen", "5 seconds"), $"animal")
.sum("howMany")
windowedCount.writeStream
.trigger(Trigger.ProcessingTime(5 * 1000))
}
}
SPARK & APPLICATION CODE INTERACTIONs
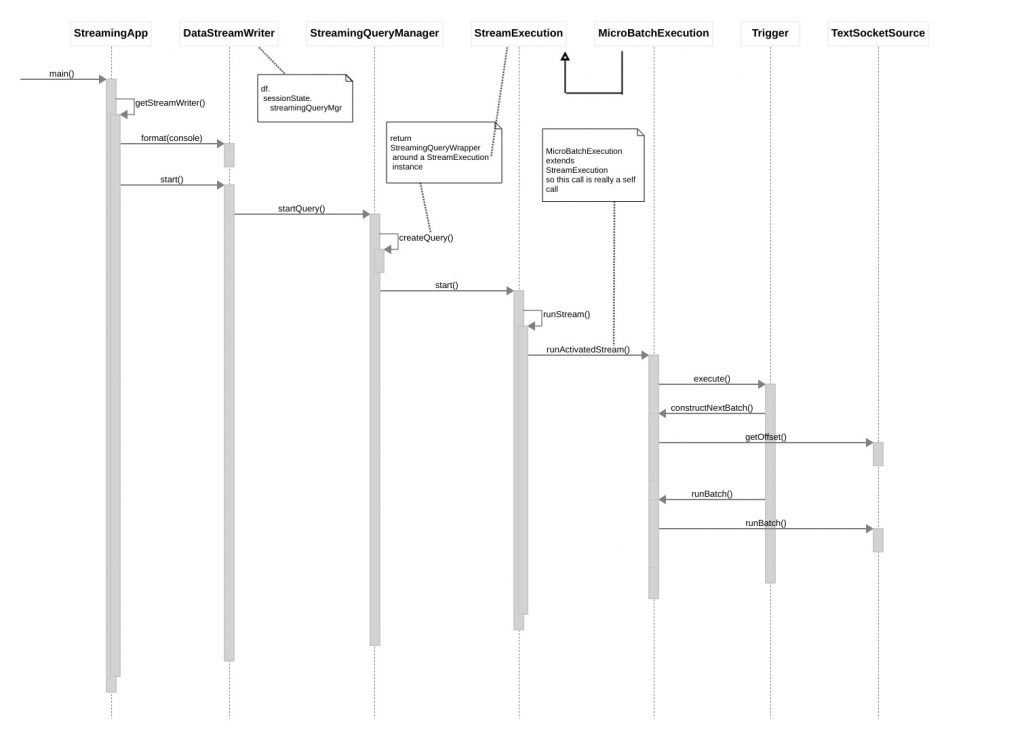
Here is a sequence diagram illustrating how Spark Stream eventually calls into our (cloned) Datasource to obtain batches of event records.
This post provides example usage of the Spark “lag” windowing function with a full code example of how “lag” can be used to find gaps in dates. Windowing and aggregate functions are similar in that each works on some kind of grouping criteria. The difference is that with aggregates Spark generates a unique value for each group, based on some calculation like computing the maximum value (within group) of some column. Windowing functions use grouping to compute a value for each record in the group.
For example, lets say you were a sports ball statistician that needs to calculate:
for each team in league: the average number of goals scored by all players on that team
for each player on each team: an ordering of players by top scorer, and for each player ‘P’, the delta between ‘P’ and the top scorer.
You could generate the first stat using groupBy and the ‘average’ aggregate function. Note that for each (by team) group, you get one value.
Input
-----
Team Player Goals
---- ------ -----
Bears
Joe 4 \
Bob 3 -> (4+3+2) /3 = 3
Mike 2 /
Sharks
Lou 2 \
Pancho 4 -> (2+4+0) /3 = 2
Tim 0 /
Output
------
Team Average
----- -------
Bears 3
Sharks 2
For the second stat (the delta) you would need the team max number of goals, and you need to subtract EACH individual player’s goals from that max.
So instead of ending up with two records (one for each team) that convey the max (per team) as done above, what you need to do here is calculate the max, m(T), for each team T (teamMax, in the snippet below) and then inject this max into the record corresponding to EACH member of team T. You would then compute the “delta” for each player on a given team T as the max for team T minus that player’s goals scored.
The associated code would look something like this:
The full code example goes into more details of the usage. But conceptually, your inputs and outputs would look something like the following:
Input
-----
Team Player Goals
---- ------ -----
Bears
Joe 4 \
Bob 3 -> max(4,3,2) = 4
Mike 2 /
Sharks
Lou 4 \
Pancho 2 -> max(2,4,0) = 4
Tim 0 /
Output
------
Team Player Goals Delta
----- ------- ----- -----
Bears Joe 4 0 <--- We have 3 values
Bears Bob 3 1 <--- for each team.
Bears Mike 2 2 <--- One per player,
Sharks Lou 4 0 <--- not one value
Sharks Pancho 2 2 <--- for each team,
Sharks Tim 0 4 <--- as in previous example
Full Code Example
Now let’s look at a runnable example that makes use of the ‘lag’ function. For this one, let’s imagine we are managing our sports ball team and we need each player to regularly certify for non-use of anabolic steroids. For a given auditing period we will give any individual player a pass for one lapse (defined by an interval where a previous non-use certification has expired and a new certification has not entered into effect.) Two or more lapses, and Yooouuuu’re Out ! We give the complete code listing below, followed by a discussion.
package org
import java.io.PrintWriter
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.types._
object DateDiffWithLagExample extends App {
lazy val sparkConf =
new SparkConf() .setAppName("SparkySpark") .setMaster("local[*]")
lazy val sparkSession =
SparkSession .builder() .config(sparkConf).getOrCreate()
val datafile = "/tmp/spark.lag.demo.txt"
import DemoDataSetup._
import org.apache.spark.sql.functions._
import sparkSession.implicits._
sparkSession.sparkContext.setLogLevel("ERROR")
val schema = StructType(
List(
StructField(
"certification_number", IntegerType, false),
StructField(
"player_id", IntegerType, false),
StructField(
"certification_start_date_as_string", StringType, false),
StructField(
"expiration_date_as_string", StringType, false)
)
)
writeDemoDataToFile(datafile)
val df =
sparkSession.
read.format("csv").schema(schema).load(datafile)
df.show()
val window =
Window.partitionBy("player_id")
.orderBy("expiration_date")
val identifyLapsesDF = df
.withColumn(
"expiration_date",
to_date($"expiration_date_as_string", "yyyy+MM-dd"))
.withColumn(
"certification_start_date",
to_date($"certification_start_date_as_string", "yyyy+MM-dd"))
.withColumn(
"expiration_date_of_previous_as_string",
lag($"expiration_date_as_string", 1, "9999+01-01" )
.over(window))
.withColumn(
"expiration_date_of_previous",
to_date($"expiration_date_of_previous_as_string", "yyyy+MM-dd"))
.withColumn(
"days_lapsed",
datediff(
$"certification_start_date",
$"expiration_date_of_previous"))
.withColumn(
"is_lapsed",
when(col("days_lapsed") > 0, 1) .otherwise(0))
identifyLapsesDF.printSchema()
identifyLapsesDF.show()
val identifyLapsesOverThreshold =
identifyLapsesDF.
groupBy("player_id").
sum("is_lapsed").where("sum(is_lapsed) > 1")
identifyLapsesOverThreshold.show()
}
object DemoDataSetup {
def writeDemoDataToFile(filename: String): PrintWriter = {
val data =
"""
|12384,1,2018+08-10,2018+12-10
|83294,1,2017+06-03,2017+10-03
|98234,1,2016+04-08,2016+08-08
|24903,2,2018+05-08,2018+07-08
|32843,2,2017+04-06,2018+04-06
|09283,2,2016+04-07,2017+04-07
""".stripMargin
// one liner to write string: not exception or encoding safe. for demo/testing only
new PrintWriter(filename) { write(data); close }
}
}
We begin by loading the input data below (only two players) via the DemoDataSetup.writeDemoDataToFile method.
Next we construct three DataFrames. The first reads in the data (using a whacky non-standard date format just for kicks.) The second uses the window definition below
val window =
Window.partitionBy("player_id") .orderBy("expiration_date")
which groups records by player id, and orders records from earliest certification to latest. For each record this expression
will ensure that for any given record listing the start date of a certification period we get the expiration date of the previous period. We use ‘datediff’ to calculate the days elapsed between the expiration of the previous cert and the effective start date of the cert for the current record. Then we use when/otherwise to mark a given player as is_lapsed if the days elapsed calculation between the current record’s start date and the previous record’s end date yielded a number greater than zero.
Finally, we compute a third DataFrame – identifyLapsesOverThreshold – which this time uses an aggregation (as opposed to windowing) function to group by player id and see if any player’s sum of ‘is_lapsed’ flags is more than one.
The final culprit is player 1, who has two lapses and will thus be banished — should have just said Noto steroids.
After reading a number of on-line articles on how to handle ‘data skew’ in one’s Spark cluster, I ran some experiments on my own ‘single JVM’ cluster to try out one of the techniques mentioned. This post presents the results, but before we get to those, I could not restrain myself from some nitpicking (below) about the definition of ‘skew’. You can quite easily skip the next section if you just want to get to the Spark techniques.
A Statistical Aside
Statistics defines a symmetric distribution as one in which the mean, median, and mode are all equal, and a skewed distribution as one where these properties do not hold. Many online resources use a conflicting definition of data skew, for example this one, which talks about skew in terms of “some data slices [having] more rows of a table than others”. We can’t use the traditional statistics definition of skew if our concern is unequal distribution of data across the partitions of our Spark tasks.
Consider a degenerate case where you have allocated 100 partitions to process a batch of data, and all the keys in that batch are from the same customer. Then, if we are using a hash or range partitioner, all records would be processed in one partition, while the other 99 would be idle. But clearly in this case the mean (average), the mode (most common value), and the median (the value ‘in the middle’ of the distribution) would all be the same. So, our data is not ‘skewed’ in the traditional sense, but definitely unequally distributed amongst our partitions. Perhaps a better term to use instead of ‘skewed’ would be ‘non-uniform’, but everyone uses ‘skewed’. So, fine. I will stop losing sleep over this and go with the data-processing literature usage of the term.
Techniques for Handling Data Skew
More Partitions
Increasing the number of partitions data may result in data associated with a given key being hashed into more partitions. However, this will likely not help when one or relatively few keys are dominant in the data. The following sections will discuss this technique in more detail.
Bump up spark.sql.autoBroadcastJoinThreshold
Increasing the value of this setting will increase the likelihood that the Spark query engine chooses the BroadcastHashJoin strategy for joins in preference to the more data intensive SortMergeJoin. This involves transmitting the smaller to-be-joined table to each executor’s memory, then streaming the larger table and joining row-by-row. As the size of the smaller table increases, memory pressure will also increase, and the viability of this technique will decrease.
Iterative (Chunked) Broadcast Join
When your smaller table becomes prohibitively large it might be worth considering the approach of iteratively taking slices of your smaller (but not that small) table, broadcasting those, joining with the larger table, then unioning the result. Here is a talk that explains the details nicely.
Convert to RDDs using Custom Partitioners, Convert Back to Dataframe
This article illustrates the technique of converting each of the to-be-joined dataframes to pair RDD’s, and partitioning them with a custom partitioner that evenly spreads records across the available partitions.
Adding salt
Add ‘salt’ to the keys of your data set by mapping each key to a pair whose first element is the original key, and whose second element is a random integer in some range. For very frequently occurring keys the range would be larger than for keys which occur with average or lower frequency.
You would add an additional salt column to both tables, then join on the customerId and the salt, with the modified input to the join appearing as shown below. Note that ‘USGOV’ records used to wind up in one partition, but now, with the salt added to the key they will likely end up in one of three partitions (‘salt range’ == 3.) The records associated with less frequently occurring keys will only get one salt value (‘salt range’ == 1), as we don’t need to ensure that they end up in different partitions.
To ensure the join works, the salt column needs to be added to the smaller table, and for each random salt value associated with higher frequency keys we need to add new records (note there are now three USGOV records.) This will add to the size of the smaller table, but often this will be out-weighed by the efficiency gained from not having a few partitions loaded up with a majority of the data to be processed.
Adding More Partitions: Unhelpful When One Key Dominates
Before we look at code, lets consider a minimal contrived example where we have a data set of twelve records that needs to be distributed across our cluster, which we will accomplish by ‘mod’ing the key by the number of partitions. First consider a non-skewed data set where no key dominates, and 3 partitions. We see partition 0 gets filled with 5 items. While partition 2 get filled with three. This skewing is a result of the fact that we have very few partitions.
Now, lets look at two skewed data sets, one in which one key (0) dominates, and another where the skewedness is the fault of two keys (0 and 12.) We will again partition by mod’ing by the number of available partitions. In both cases, partition 0 gets flooded with 8 of 12 records. Other partitions get only 2 records.
Now let’s see what happens when we increase the number of partitions to 11, and distribute records across partitions by mod’ing by the same number. In the case where one key (0) dominates, we find that partition 0 still gets 7 out of 12 records. But when the ‘skew’ is spread across not one, but two keys (0 and 12), we find that only 3 out of 12 records end up in partition zero. This shows that the more ‘dominance’ is concentrated around a small set of keys (or one key, as often happens with nulls), the less we will benefit by simply adding partitions.
Skewed Data Set -- One Key (0) Dominates
key partition
* 0 0
* 0 0
* 0 0
1 1
2 2
3 3
4 4
5 5
* 6 6
* 0 0
* 0 0
* 0 0
Skewed Data Set -- No Single Key Dominates (0/12 are most likely)
key partition
* 0 0
* 0 0
* 0 0
1 1
2 2
3 3
4 4
5 5
6 6
12 1
12 1
12 1
Adding More Partitions: A Simple Test Program
The main processing component of the test program I developed to explore what happens with skewed data does a mapPartitionsWithIndex over each partition of a Pair RDD with each pair consisting of the key, followed by the value. The keys are generated by the KeyGenerator object which will always generate 100 keys, either as a uniform distribution from 1 to 100, or as two flavors of skewed distribution, both of which have 55 random keys. The ‘oneKeyDominant’ distribution augments the 55 random keys with 55 0’s, while the ‘not oneKeyDominant’ distribution uses 3 high frequency keys: 0, 2, and 4, occurring 18, 18, and 19 times, respectively.
At the beginning of the mapPartitionsWithIndex we start a timer so we can see how much time it takes to completely process each partition. As we iterate over each key we call ‘process’ which emulates some complex processing by sleeping for 50 milliseconds.
def process(key: (Int, Int), index: Int): Unit = {
println(s"processing $key in partition '$index'")
Thread.sleep(50) // Simulate processing w/ delay
}
keysRdd.mapPartitionsWithIndex{
(index, keyzIter) =>
val start = System.nanoTime()
keyzIter.foreach {
key =>
process(key, index)
}
val end = System.nanoTime()
println(
s"processing of keys in partition '$index' took " +
s" ${(end-start) / (1000 * 1000)} milliseconds")
keyzIter
}
.count
}
The full code is presented in full below. As long as you use Spark 2.2+ you should be able to run this code by copy/pasting into any existing Spark project you might have. To reproduce the results we report in the next section, you need to manually set these variables: numPartitions , useSkewed, oneKeyDominant before you launch the application.
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
import scala.collection.immutable
import scala.util.Random
object KeyGenerator {
val random = new Random()
def getKeys(useSkewed: Boolean,
oneKeyDominant: Boolean) : immutable.Seq[Int] = {
def genKeys(howMany: Int,
lowerInclusive: Int,
upperExclusive: Int) = {
(1 to howMany).map{ i =>
lowerInclusive +
random.nextInt(upperExclusive - lowerInclusive)
}
}
val keys =
if (useSkewed) {
val skewedKeys =
if (oneKeyDominant)
Seq.fill(55)(0)
else
Seq.fill(18)(0) ++ Seq.fill(18)(2) ++ Seq.fill(19)(4)
genKeys(45, 1, 45) ++ skewedKeys
}
else {
genKeys(100, 1, 100)
}
System.out.println("keys:" + keys);
System.out.println("keys size:" + keys.size);
keys
}
}
object SaltedToPerfection extends App {
import KeyGenerator._
def runApp(numPartitions: Int,
useSkewed: Boolean,
oneKeyDominant: Boolean) = {
val keys: immutable.Seq[Int] = getKeys(useSkewed, oneKeyDominant)
val keysRdd: RDD[(Int, Int)] =
sparkSession.sparkContext.
parallelize(keys).map(key => (key,key)). // to pair RDD
partitionBy(new HashPartitioner(numPartitions))
System.out.println("keyz.partitioner:" + keysRdd.partitioner)
System.out.println("keyz.size:" + keysRdd.partitions.length)
def process(key: (Int, Int), index: Int): Unit = {
println(s"processing $key in partition '$index'")
Thread.sleep(50) // Simulate processing w/ delay
}
keysRdd.mapPartitionsWithIndex{
(index, keyzIter) =>
val start = System.nanoTime()
keyzIter.foreach {
key =>
process(key, index)
}
val end = System.nanoTime()
println(
s"processing of keys in partition '$index' took " +
s" ${(end-start) / (1000 * 1000)} milliseconds")
keyzIter
}
.count
}
lazy val sparkConf = new SparkConf()
.setAppName("Learn Spark")
.setMaster("local[4]")
lazy val sparkSession = SparkSession
.builder()
.config(sparkConf)
.getOrCreate()
val numPartitions = 50
val useSkewed = true
val oneKeyDominant = true
runApp(numPartitions, useSkewed, oneKeyDominant)
Thread.sleep(1000 * 600) // 10 minutes sleep to explore with UI
}
Adding More Partitions: Test Results
The results obtained from running our test program accorded with the informal analysis we performed above on various cardinality=12 data sets, namely, that increasing the number of partitions is more helpful when more than one key dominates the distribution. When one key dominates, increasing partitions improved performance by 16% (see difference between runs 3 and 5), whereas when multiple keys dominate the distribution we saw an improvement of 29% (see difference between runs 2 and 4.)
Run Partitions Skew Job Duration
1 4 none 2.057556 s
2 4 multiple dominant keys 3.125907 s
3 4 one dominant key 4.045455 s
4 50 multiple dominant keys 2.217383 s
5 50 one dominant key 3.378734 s
Performance improvements obtained by increasing partitions (4->50)
one dominant key
Elapsed time difference between run 3 and 5
(4.045455 - 3.378734) / 4.045455 = 16%
multiple dominant keys
Elapsed time difference between run 2 and 4
(3.125907 - 2.217383) / 3.125907 = 29%
I recently worked on a project where the ‘contract’ between service consumers and providers consisted primarily of annotated mock-ups of the JSON responses one would obtain from each of a given service’s end-points. A much better way of expressing the contract for a service is to use a standard schema format. If your stuck with XML, use XML schema. If you are using JSON then there are tools and libraries (presented below ) which will help you use JSON schema to express a service’s contract. This article will assume that you have gone through the available JSON schema documentation and have a basic ideas of how to use it. It assumes that you are developing on a JVM-based platform, and most of the recipes will be helpful for Java developers (although our example of dynamic schema validation is presented using a bit of Scala.)
Why Use JSON Schema As Your Contract ?
Suppose you are supporting a JSON-based service, with your contract expressed in some type of “by-example” format rather than the JSON schema standard. Now one of the components consuming your service throws an exception while parsing a response. The developer of said client service comes to you and says “your service has a problem”. Well, both of you then have to pore over the examples that define your service’s responses and figure out if the response sent in this instance honors or violates the implicit contract. This is a very manual process with room for mistakes, and at the worst, can lead to finger pointing and debates about whether the response is correct. Not fun.
However, if the server and client teams on your project come to agreement on a schema for each JSON response, then the task of figuring out if a given response is correct boils down to simply running a validation tool where the inputs are the response document in question, and the schema to which it must conform. If the validator reports no errors then you are off the hook, with no debate.
Json Schema Tools
This section describes how to install and use various tools for auto-generation of JSON schema from sample documents, generation of sample instance documents from schema, and schema validation. As long as your environment is configured with Java 1.8, Python 2.7+, and the pip installer, then the provided set-up instructions should work on either Linux or Mac (at least they worked for me!)
Auto-generating JSON Schema From Instance Documents
genson is a utility for auto-generating JSON schema from instance documents. It can be installed via the command
sudo pip install genson==0.1.0 # install it
Next try generating a schema for a simple document.
Sometimes you will be generating multiple schemas from a related set of JSON documents (e.g., you might be starting from a set of sample responses from a legacy service with no defined schema, which you plan to retrofit .) In this case you will definitely want to familiarize yourself with the $ref keyword which lets you refactor commonly occurring fragments of schema code into one place (even a different file.)
generation of sample instance documents from schema
Once you have a schema you can feed it into a tool, such as this one from Liquid Technologies, to facilitate generation of mock data that you can use for testing.
Command LINE TOOLS FOR Schema validation
The best command line tool I have found for JSON schema validation is json-schema-validator. Its current documentation indicates support for JSON Schema draft v4 which is a bit behind the latest draft (7, at the time of this writing.) So, if you need the latest spec-supported features in your schemas, you should take extra care to ensure this tool is right for your needs.
Assuming you have gone through the previous step of installing and testing genson, you can download and verify the validator via the commands below (if you are on a Mac without wget, then please try curl):
wget 'https://bintray.com/fge/maven/download_file?file_path=com%2Fgithub%2Ffge%2Fjson-schema-validator%2F2.2.6%2Fjson-schema-validator-2.2.6-lib.jar' -O /tmp/validator.jar
# now validate your sample document against the schema you created above
cd /tmp ; java -jar validator.jar /tmp/foo.schema /tmp/foo.json
You should see:
validation: SUCCESS
Now let’s see how the tool reports validation failures. Deliberately mess up your instance document (so it no longer conforms to the schema) via the command:
cat /tmp/foo.json | sed -e's/foo/zoo/' > /tmp/bad.json
cd /tmp ; java -jar validator.jar /tmp/foo.schema /tmp/bad.json
You should see error output which includes the line:
"message" : "object has missing required properties ([\"foo\"])",
On THE FLY SCHEMA VALIDATION At RUN-TIME
When previously discussed, the json-schema-validator was shown in command line mode. As a bonus you can also embed this this project’s associated Java library into any of your services that require run-time validation of arbitrary instance documents against a schema. The code snippet below (available as a project here) is written in Scala, but you could easily use this in Java projects as well.
val goodResult = validateWithReport(FakeGoodWebService.getJsonResponse) System.out.println("result:" + goodResult);
val badResult = validateWithReport(FakeBadWebService.getJsonResponse) System.out.println("result:" + badResult); }
We have stashed the ‘foo’ schema from our previous discussion into src/main/resources and the object constructor for SchemaValidator loads that schema into the ‘schema’ variable. We then call validateWithReport from JsonSchemaValidationDemo first with a valid response from a mock of a nicely behaving web service, then we feed validateWithReport a JSON response from a misbehaving web service. The resultant output is shown below.
Miscommunication and incorrect assumptions are most likely at what formally trained project managers call “interface points at subsystem boundaries” (you can read up more here.) But now you have some tools for minimizing the thrash and churn that can occur around these interface points.